
Quick Summary: Plain English Identity Query AI is the heart of Oleria Trustfusion, an AI-native identity security platform — ask any question about access, risk, or activity in natural language and get verified, hallucination-free answers drawn directly from your identity graph in seconds.
Identity, access, activity, risk — one conversational surface. The AI picks the right answer shape for the question, against verified data.
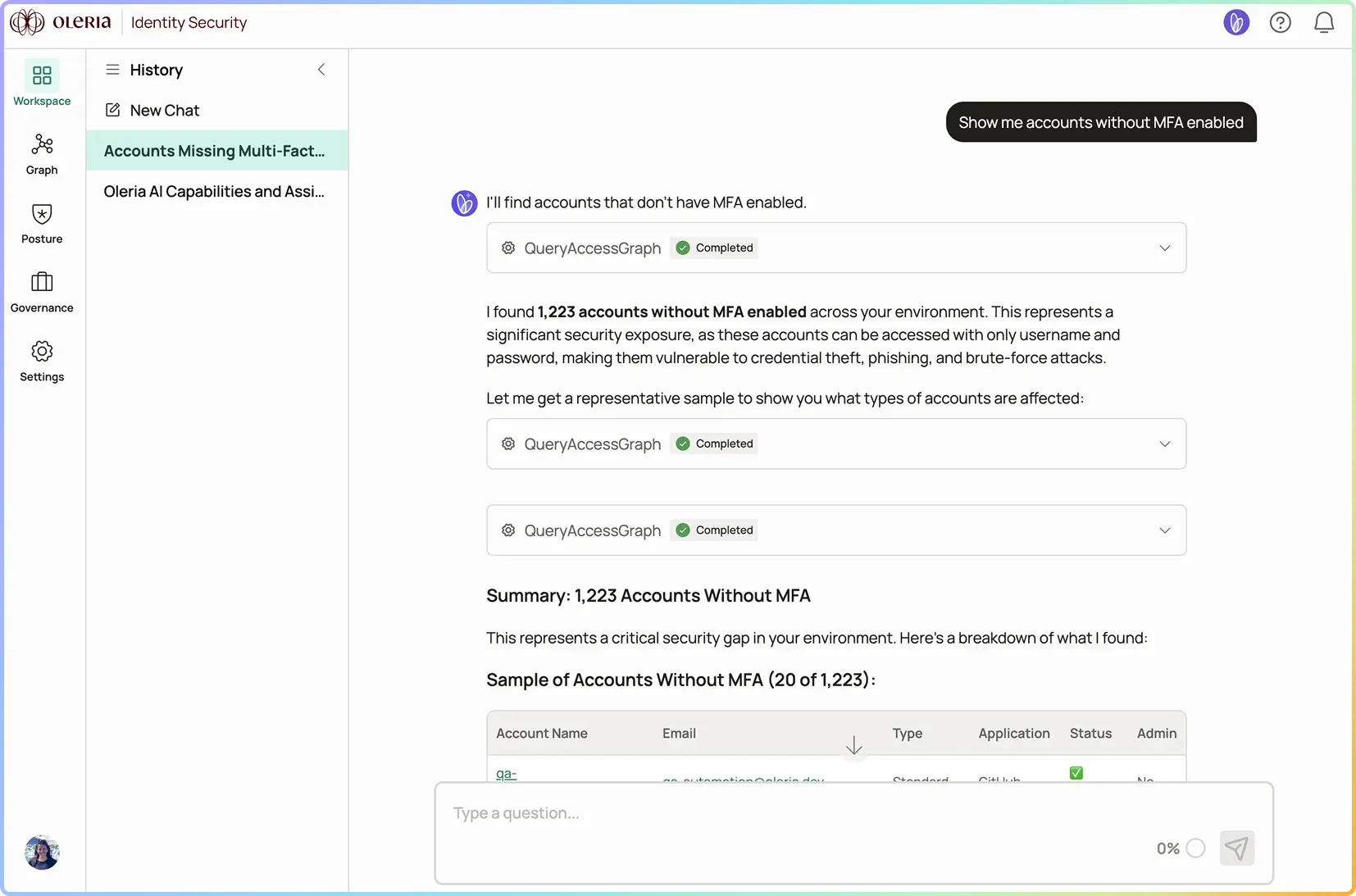
Identity questions in plain language don't map cleanly to query syntax. "Who has access to customer data," "is this service account behaving abnormally," "how is our MFA posture this quarter" — each requires a different system, a different query language, and a different report. The IAM engineer ends up chasing data across five tools instead of answering the question.
Plain-English query is a hard AI problem because the answer isn't text — it's a query against structured data that has to return verified, citation-able answers. Hallucinated identities or fabricated counts in identity questions are dangerous; the SOC making decisions on hallucinated data is worse than no answer at all. The bar is correctness, not just fluency. Plain English Identity Query AI only works when the underlying data model is complete and the AI is grounded in real graph data — which is exactly what Oleria Trustfusion provides.
Oleria's Plain English Identity Query AI surfaces access paths, risk signals, and activity patterns from your live identity graph — verified data, adaptive answer shapes, no hallucinations.
Identity and access graph, activity and usage, risk catalog, metrics. The AI translates the question, picks the right data source(s), and returns the answer.
The AI picks the format that fits. Who has access to X? → list of identities. Why does Alice have it? → the access path. Is this NHI behaving abnormally? → the activity pattern with deviation. How is our MFA posture? → the metrics summary. The shape follows the question.
Answers come from the actual graph, activity logs, risk catalog, or metrics — not generated text. No hallucinated identities, permissions, or counts. If the data isn't there, the AI says so.
Follow-up questions narrow or expand. "Filter to the last 30 days," "include service accounts," "now show me the same for finance." Conversational rather than start-over.
The Copilot reads from the access graph, activity logs, risk catalog, and metrics — chooses the right source per question, shapes the answer to fit, and never generates identity data. Translation is AI; the answer is data.
Time to answer ad-hoc identity questions Hours of query writing → seconds
Operators who can ask identity questions IAM engineers → anyone with permission
Hallucinated data in answers Zero (verified against real Oleria data)
Tool-switching to chase identity data Eliminated

Anything answerable from the data Oleria has. Access graph: who has access to what, who can reach what across role chains, what's the blast radius for this user. Activity and usage: who logged in from where, which permissions are dormant, is this NHI behaving abnormally. Risk: which apps have the worst hygiene posture, where are the privileged-access concentrations. Metrics: account counts, MFA coverage, dormancy aggregates. Cross-domain questions are supported in the same conversation.
By the question. "Who has access to X" returns a list of identities; "why does Alice have access" returns the access path; "is this NHI behaving abnormally" returns the activity pattern with the deviation flagged; "how is our MFA posture" returns a metrics summary. The Copilot picks the format that answers the question — no fixed template.
Hallucinated data is structurally impossible because data is read from real Oleria sources, not generated. The AI translates the question into a query against the graph, activity logs, risk catalog, or metrics; the query runs against real data; the answer is rows, paths, or aggregates from that data. The AI does not generate identity names, permission names, or counts — those come from the source.
The AI says so. "This question requires data that isn't in Oleria — specifically, X." The operator can adjust the question, or recognize that the question needs a different system. The failure mode is honest, not hallucinated.
Yes. The AI can pull from the graph, activity, risk, and metrics in the same conversation — and follow-up questions can pivot across them. "Who has access to the customer database" (graph) → "which of these have used it in the last 30 days" (activity) → "any with risky posture on their account" (risk). One thread, multiple sources.


